TL;DR:
Robot policy learning with an active mechanical eyeball
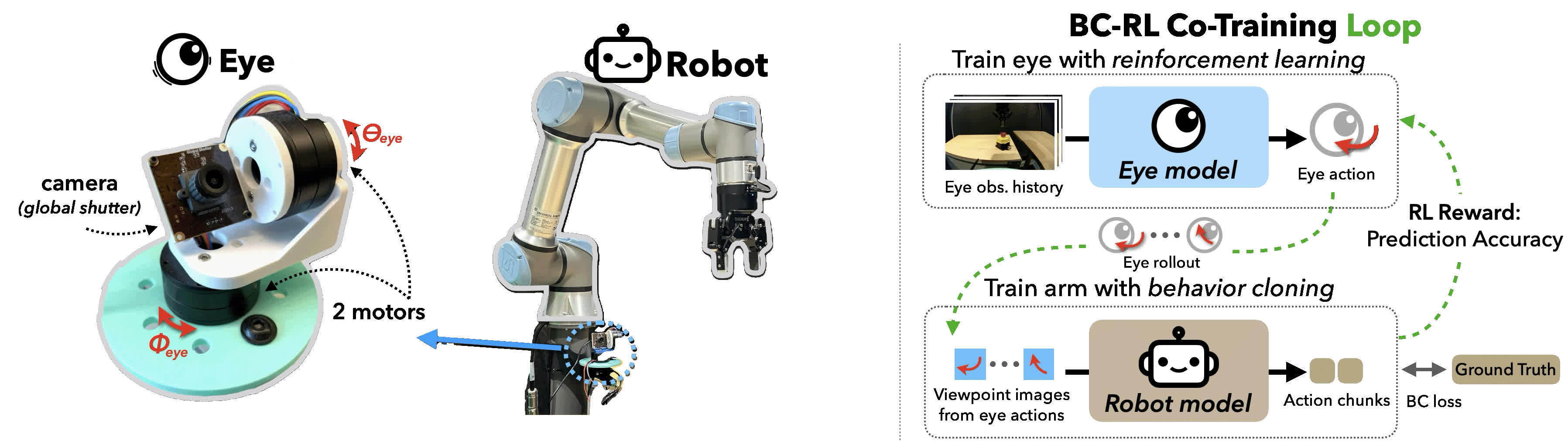
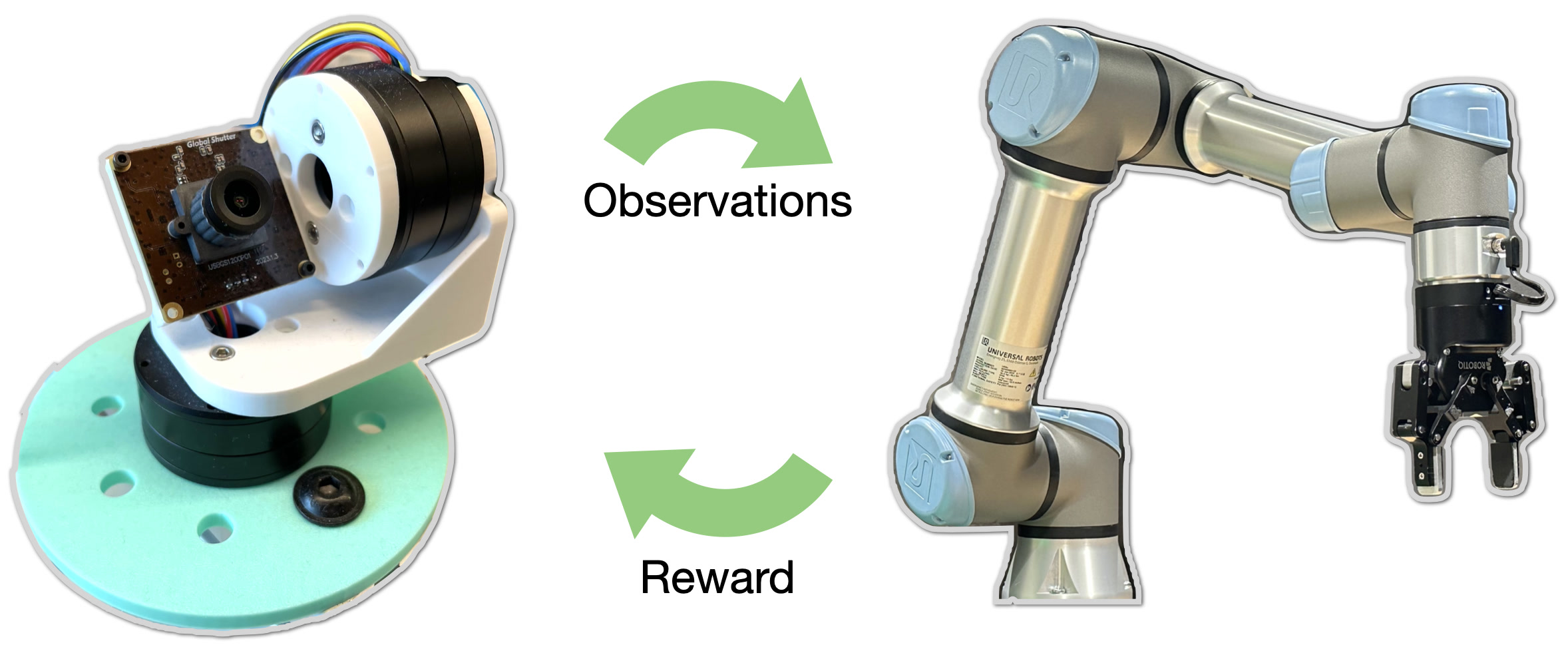
We train eyeball and arm policies jointly through a BC-RL loop which frames eye gaze as
an RL agent that continuously optimizes the performance of a BC policy.
Gaze for Real-World Manipulation
Eyeball Perspective
How it works
Real-to-Sim EyeGym
We capture robot demonstrations with a 360° camera and import this into an RL environment for simulating eye views.
EyeGym only simulates eye view, keeping the trajectory of the arm fixed.
BC-RL Cotraining
During BC-RL co-training, eye actions are sampled to obtain observations for training a BC ACT policy.
The eyeball is rewarded when the robot arm predicts accurate actions, leading to gaze behavior that facilitates action.
The RL agent (eye) and BC agent (arm) are co-trained together on the same data, jointly learning to act, and look to enable action.
Left shows random eye actions, while the right shows intentional gaze behavior in EyeGym after convergence.
Before BC-RL
After BC-RL
Gaze Switching in Real
This task-driven gaze learned in sim transfers to real;
the eye shifts from towel to bucket depending on the state of the arm.
In these videos the arm is free-driven while the eye policy is executing autonomously.
Eyeball Hardware
We design a performant camera gimbal which consists of two direct drive motors, which can move very quickly, precisely, and smoothly.
We use a 90fps global shutter camera, enabling smooth vision despite fast motion.
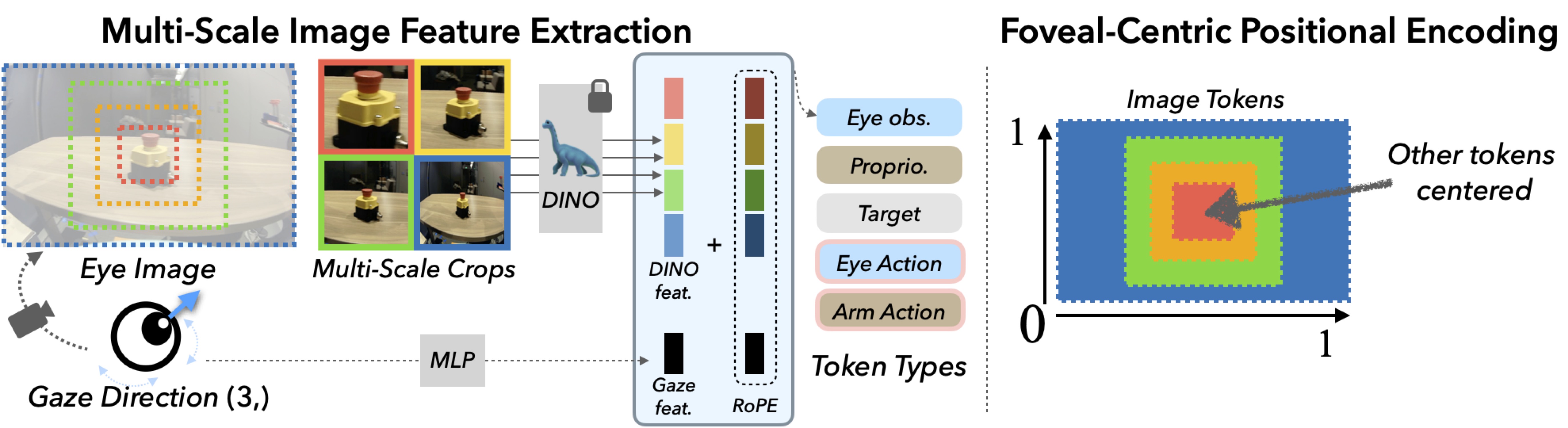
Foveated Transformer Architecture
We extract features in a multi-scale pyramid, enabling a small, high-resolution fovea along with a larger peripheral field of view.
These features are positionally encoded with nested 2D RoPE embeddings to consistently overlay image tokens, while other query tokens in the model are positioned at the center of the image.
Robustness to Distractors
Foveation aids the model in focusing on the target object while ignoring distractors.
Uniform Resolution
Foveated
Uniform Resolution
Foveated Inputs
Distance Invariance from Foveation
Multi-scale feature extraction allows the model to focus on even very distant objects (even outside of what it was trained on).
Uniform Resolution
With Foveation
Wrist and Exo Baselines
Alone, wrist cameras and exo cameras fail due to either lack of visual search or lack of precision.
With both combined, policies regain large-workspace performance, but interestingly still suffer in precision compared to wrist-only inputs,
which we hypothesize is because of the large number of irrelevant image tokens increasing the risk of overfitting with low data.
Failures
Failure cases are primarily due to poor depth perception of the model, owing to the low-angle position of the camera.
Secondly, long-range search can fail to locate an object
In addition, we observe occasional blind grasps where the arm grasps the mean of the data when no object is in view (i.e grasping to the far left or right if the eye cannot see the towel).
Citation
If you use this work or find it helpful, please consider citing: (bibtex)
@inproceedings{kerrj2025eyerobot,
title={Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop},
author={Justin Kerr and Kush Hari and Ethan Weber and Chung Min Kim and Brent Yi and Tyler Bonnen and Ken Goldberg and Angjoo Kanazawa},
booktitle={9th Annual Conference on Robot Learning},
year={2025},
url={http://arxiv.org/abs/2506.10968}
}